作为一个视频制作人员,每天不是在找素材,就是在找素材的路上,曾无数次试想过有没有什么工具可以无脑输出高质量视频内容的,果不其然,在一番不懈努力下,还真被我给找到了!
下面大鹏就将它们倾囊相授,一一分享给大家,即使是视频小白用完也能分分钟做出爆款视频,快来看看有没有你需要的吧~
✨图文成片
首先给大家分享的这款是现阶段市面上比较常见的图文成片类AI视频工具,也就是通过AI技术来将我们所输入的文本内容转换成短视频。相对来讲它的使用门槛还是比较低的,特别适合刚入门视频制作的新手小白使用~
在视频内容个性化定制这方面也比较随性,支持我们根据自己的实际需要来修改字体样式、颜色、大小、LOGO位置等等内容。
✨数字人播报
看似只是一款简单的转语音工具,实际上它却内搭有AI虚拟人播报、AI写作、图片转文字、翻译等多项实用功能。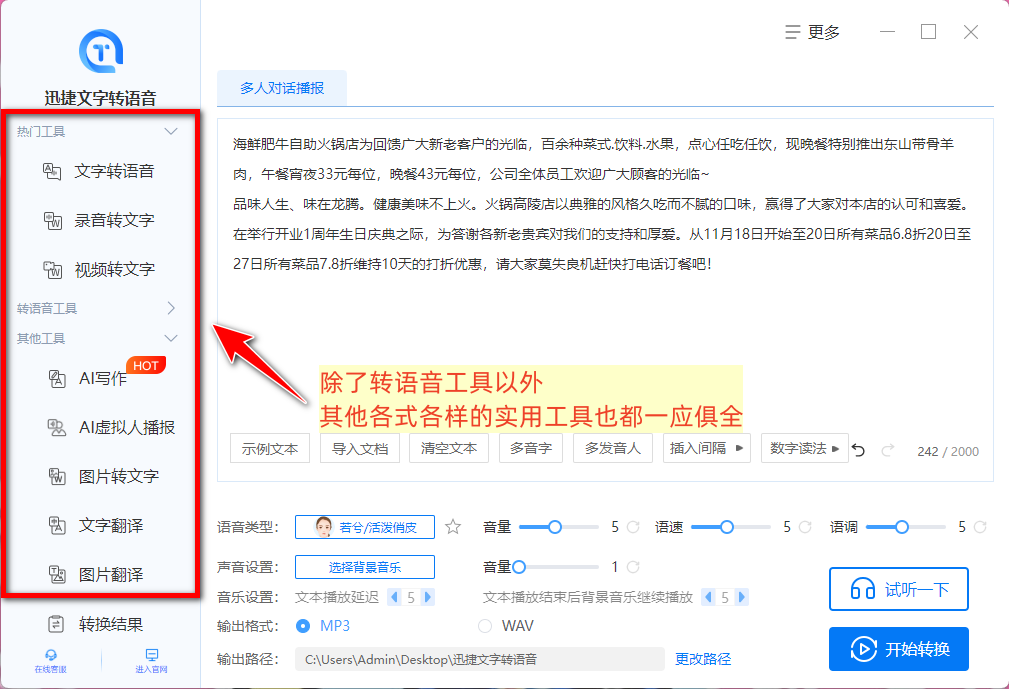
像我平时如果需要制作数字人播报视频就会经常使用到其中的「AI虚拟人播报」这一功能,输入文本/导入播报内容素材即可制作出动态播报视频,直接省去了找主播拍视频素材再剪辑的这一环节。
不仅制作方便、成本低、效率高以外,创作还十分自由~
提供有上百种不同风格、不同音色、不同声线的情感主播类型可供任意搭配使用,适合的应用场景也相当广泛,不管是影视解说、有声阅读,还是商务宣传、广告叫卖等等场景都会有相符合的选项可选择。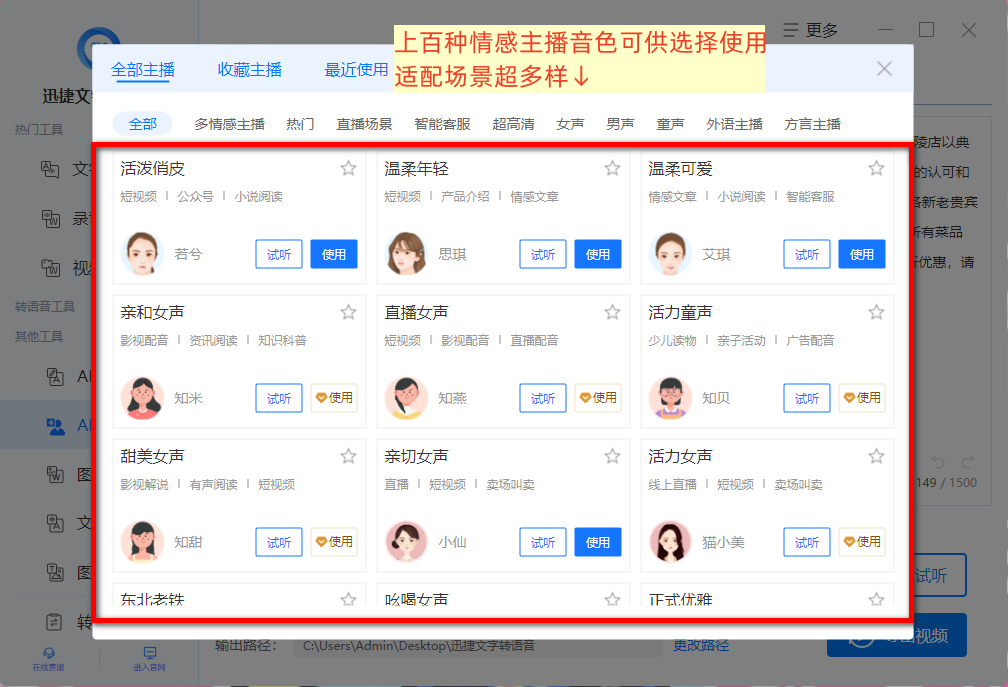
在视频画面的定制效果上也是蛮不错的,比如说主播角色、人物位置/大小、画面背景、视频画面比例这些内容都是支持按需随意修改的。
另外,我个人最爱的一点是,在制作视频的过程中完全不用害怕出错,它所配备的试听功能就很方便我们随时对有需要修改的部分进行反复调整,直至满意再导出也是OK的~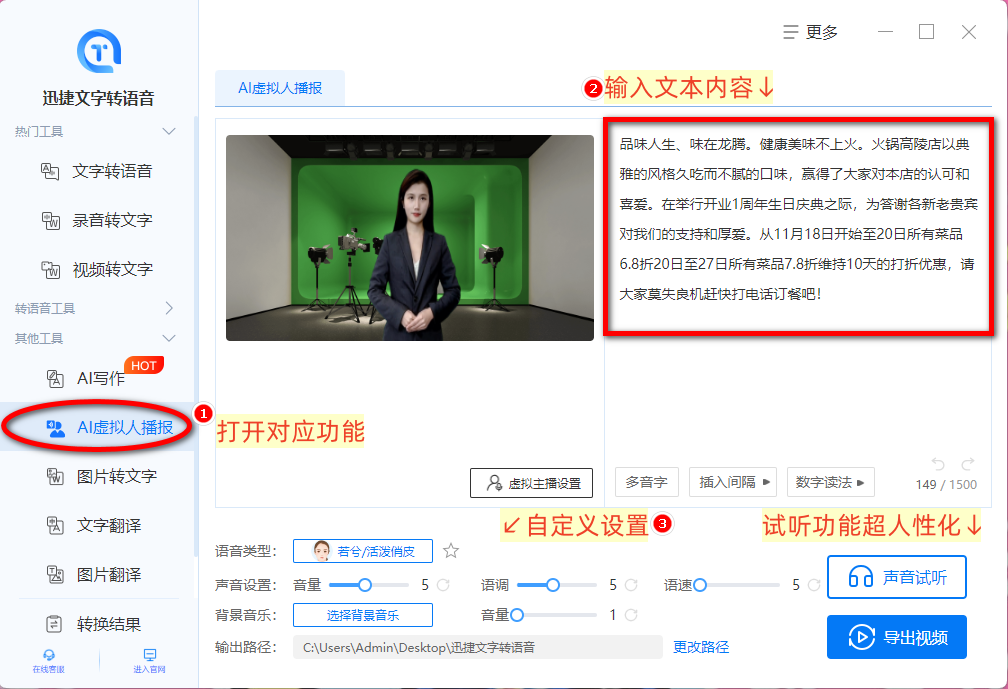
✨视频指令创作
同样是一款可以帮助我们快速、轻松创建出高质量视频的AI视频生成工具,与前面分享的两款工具有所不同的是,你只需要输入一个创作提示,它就能够根据你提供的指令快速生成合适的视频。
在软件生成视频后,还支持通过更改文本、画外音、音乐和视觉效果来自定义视频内容。
✨动画视频制作
如果题主想要制作的视频方向是动画类的话,那么不妨可以试试这一国外开源的AI动画视频扩展插件。
它的优点就在于不需要预先训练大量的数据,仅针对现有的各种Stable Diffusion微调模型就能够生成多样化和趣味性比较浓厚的动画成片。✨最后再给大家附上4点视频制作的注意事项:选择素材和话题时尽量避开敏感事件,否则过审几率会降低,轻则限流,重则封号;视频的风格色调最好保持一致,片头或片尾可以更具有记忆点;视频内容切忌过长,过长的视频完播率低会影响视频推流,在1分30秒之内最为稳妥;虽然借助以上分享的视频工具可以帮助我们提高视频制作效率,但切勿操之过急,一日之内发布数量最好不要超过3条,以质量为重。
又是干货满满的分享,我看谁还没点赞收藏喜欢,有什么意见也可以在评论区直说 @视频编辑助手 绝对欢迎大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!!
Moonvalley,号称地表最强的 「AI 视频生成工具」,到底有多厉害?今天一起来看一下~
这是 Moonvalley 官网的介绍:Moonvalley 是一个开创性的新型文本到视频的生成式 AI 模型。用简单的文本即可创建出惊人的电影和动画视频。
下面这些,都是通过 Moonvalley,用简单的文本描述生成的。


Moonvalley 和 Midjourney 一样,都是搭在 Discord 上的。
所以第一步,注册/登录 Discord:https://discord.com
登录后,点击红框中的图标「探索可发现的服务器」
在搜索框中输入「Moonvalley」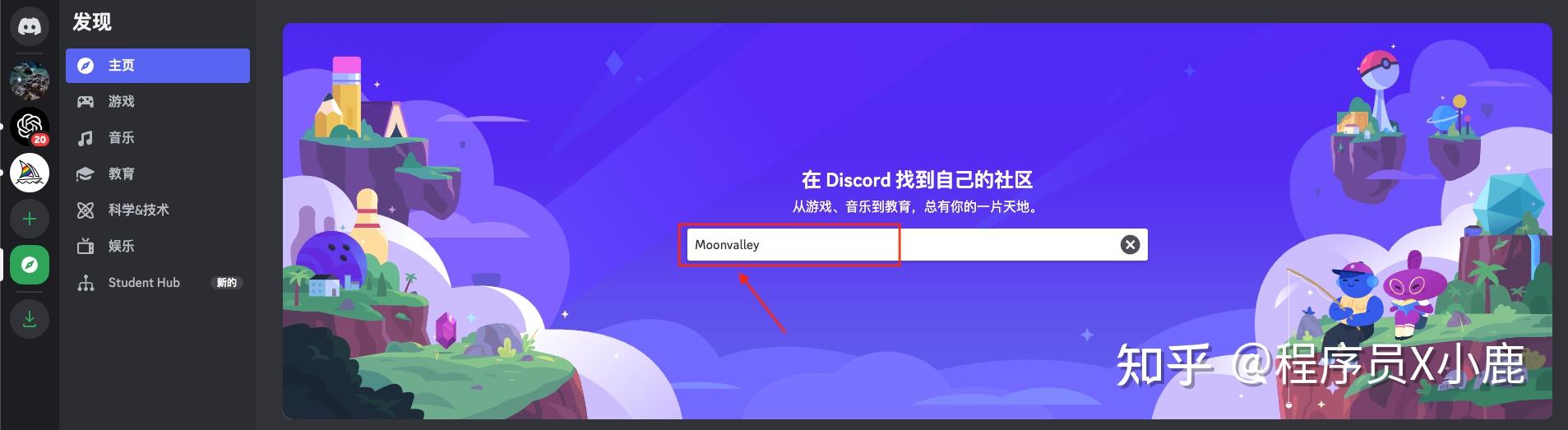
点进去 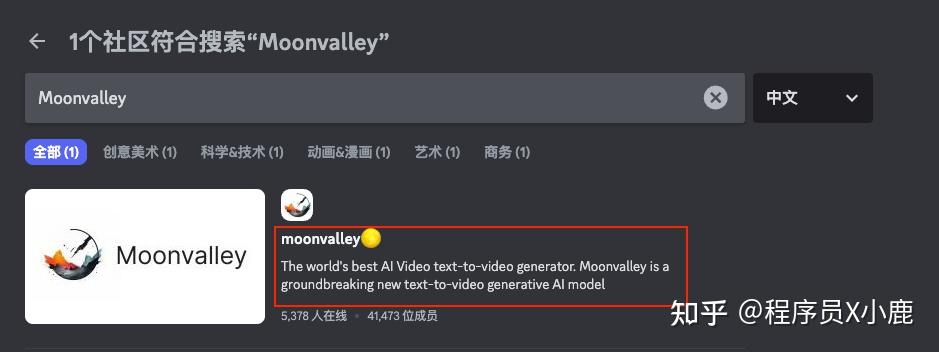
点「加入 moonvalley」大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!
然后会弹出 4 个问题,根据自己情况回答就好了,最后点「完成」。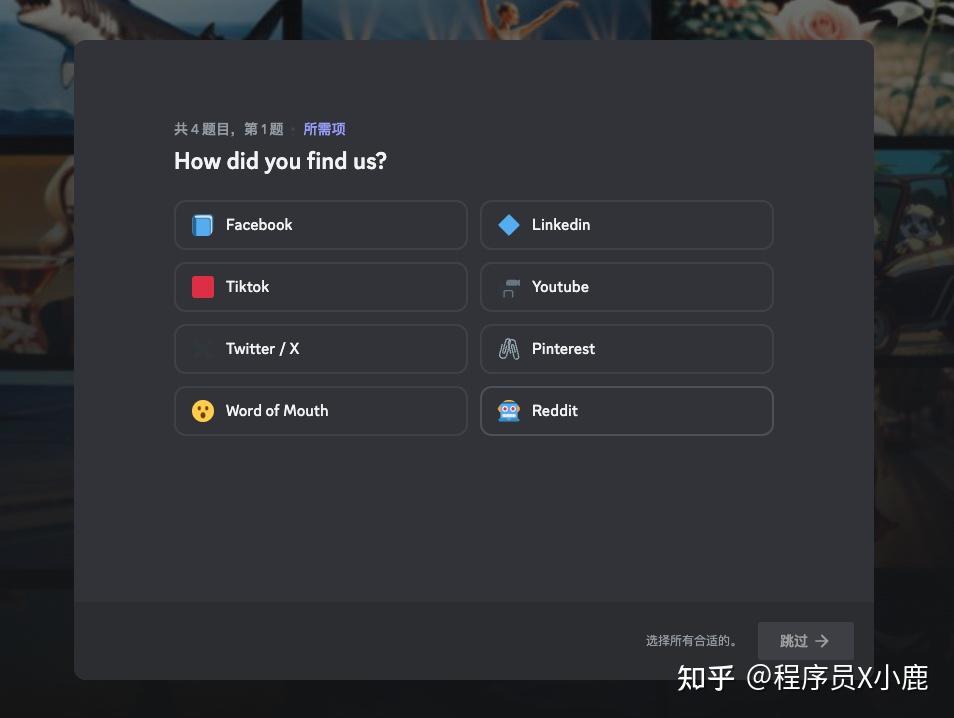
这是进入 Moonvalley 之后的界面。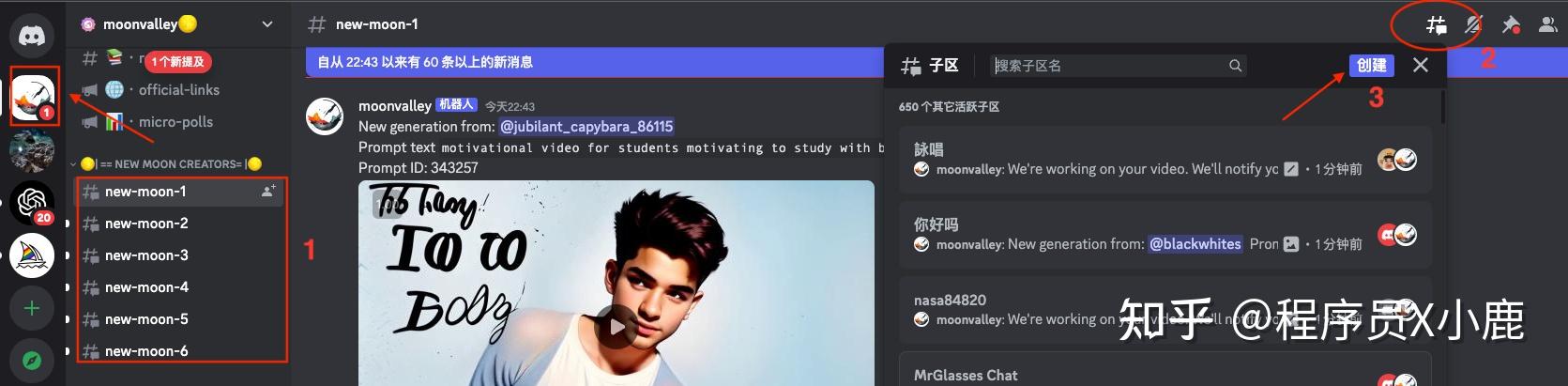
左侧 1 区,是 Moonvalley 的 6 个公共会话区域,任意点击一个进去,就可以开始生成视频了。
但由于是公共区域,所以我们生成的视频,可以被所有人看到。同样,我们也可以看到其他人生成的视频。
为了防止我们生成的视频被刷走,一般会自己单独建立一个子区。
建立子区的方式:
选择公共区域的任何一个点进去,然后点击上图「2」所示的图标,再点「创建」。
输入「子区名称」并随意输入「一条消息」,就可以开始对话了。如下图所示。
输入框中输入 /create,然后依次按照提示输入参数即可。
其中, prompt、style、duration 这三项是必选,negative 和 seed 是可选。
输入我们想生成视频的描述词(英文)。可以按 Midjourney 的提示词规则来写。
示例中的提示词供参考:
目前有这 5 种风格:
Comic book:连环漫画
Fantasy:幻想
Anime/Manga:动画
Realism:写实
3D Animation:3D 动画
不同的风格都可以试一试。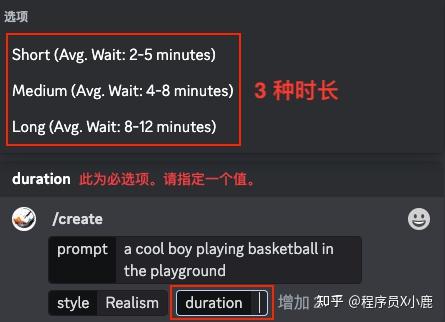
Short:视频时长 1 秒,平均等待 2-5 分钟
Medium:视频时长 3 秒,平均等待 4-8 分钟
Long:视频时长 5 秒,平均等待 8-12 分钟
负向提示词
种子。和 Midjourney 和 Stable Diffusion 中的 seed 一个意思。
最后,觉得视频满意,就可以点「下载」了。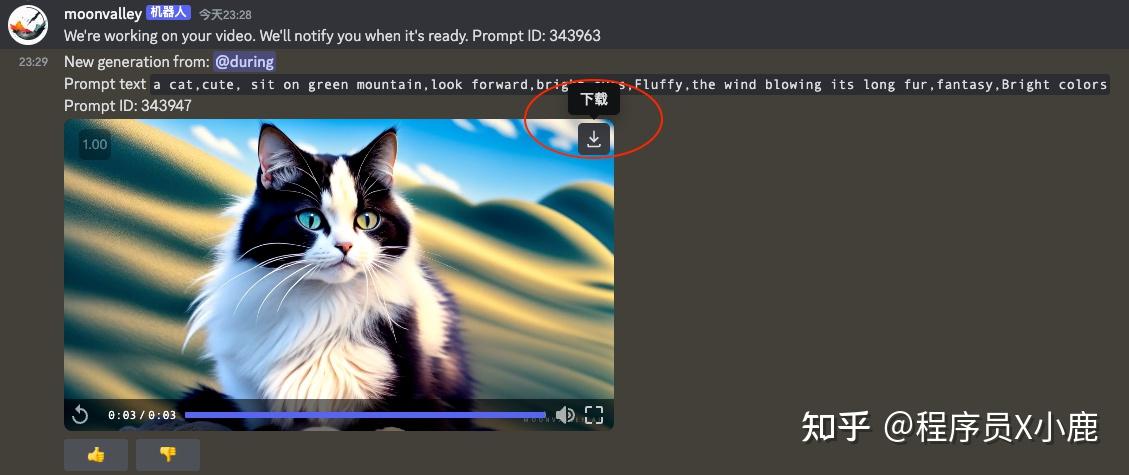
下面是使用相同的提示词、不同的风格,生成的视频,大家可以感受一下。
 AI视频生成工具Moonvalley-Comichttps://www.zhihu.com/video/1703836024608968705
AI视频生成工具Moonvalley-Comichttps://www.zhihu.com/video/1703836024608968705
 AI视频生成工具Moonvalley-幻想https://www.zhihu.com/video/1703836331250339840
AI视频生成工具Moonvalley-幻想https://www.zhihu.com/video/1703836331250339840
 AI视频生成工具Moonvalley-动漫https://www.zhihu.com/video/1703839198350618624
AI视频生成工具Moonvalley-动漫https://www.zhihu.com/video/1703839198350618624 AI视频生成工具Moonvalley-写实https://www.zhihu.com/video/1703836742153555968
AI视频生成工具Moonvalley-写实https://www.zhihu.com/video/1703836742153555968
 AI视频生成工具Moonvalley-3Dhttps://www.zhihu.com/video/1703836815159648256
AI视频生成工具Moonvalley-3Dhttps://www.zhihu.com/video/1703836815159648256
好了,以上就是今天想分享的内容~
在2023这个AI元年里,用AI来生成视频早就已经是司空见惯的现象了~不同的AI与视频结合产出的AI视频工具功能作用也有所不同。
今天趁此机会,就让俊仔来给大家介绍一些常见的AI视频产物吧~
提及数字人播报层面,D-ID可以说是相当有名,作为国外一个专门提供AI虚拟人影片制作的平台,它以支持便捷高效地制作多个虚拟人形象而收获了一众喜爱。
制作时,我们只需上传人物照片并输入要播报的内容,AI语音机器人就能自动将其转换成音频;甚至还可以直接上传录音文件,从而快速获得一部极具真实感的合成影片。
这些影片可以应用于短视频、亲人照片、虚拟讲师、主持人、AI机器人特效等多个场景。
当然,不仅国外有虚拟数字人播报工具,国内也有一些很出彩的数字人视频制作工具~像俊仔一直在用的这款文字转语音软件在经历了不断的升级和更迭过后,也配备了【AI虚拟人播报】的功能。
这一功能主要就是集合了真人主播形象和语音播报来生成完整的视频,在新闻、娱乐、宣传、营销等多个场景下均适用。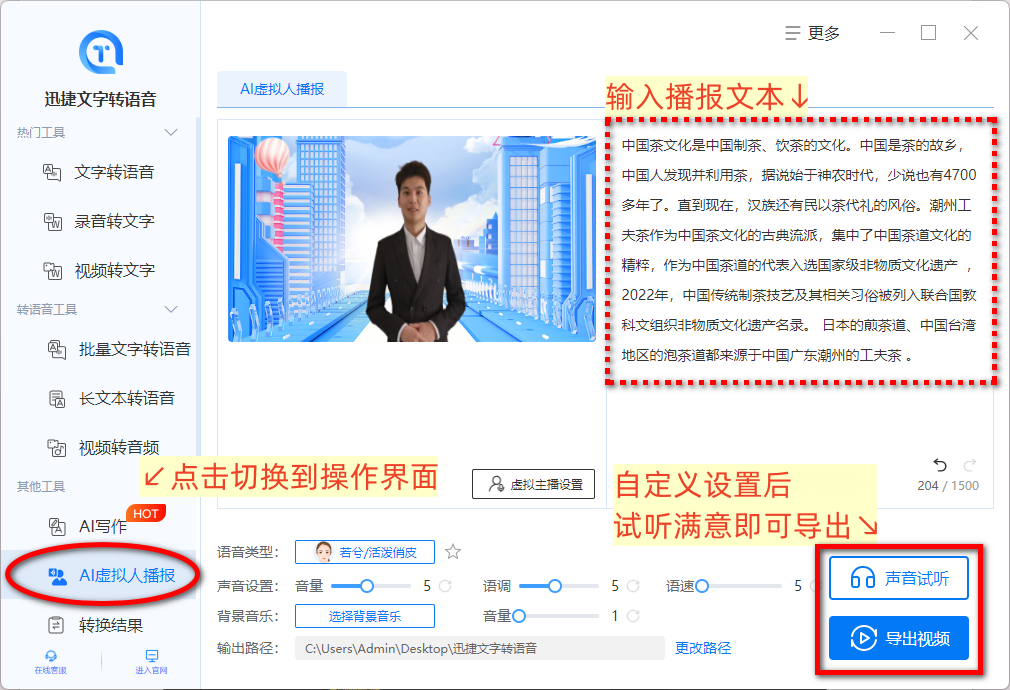
只要一键导入文本,设置相关画面内容、主播音色、语音、语调、语速等内容后导出即可,无论你是剪辑新手,还是视频大佬,统统都能轻松制作出满意的播报视频~
另外,在个性化定制这方面更是没得说,不仅支持自定义主播样貌以及好看的背景样式,同时还支持按需/按喜好挑选心仪的配音效果。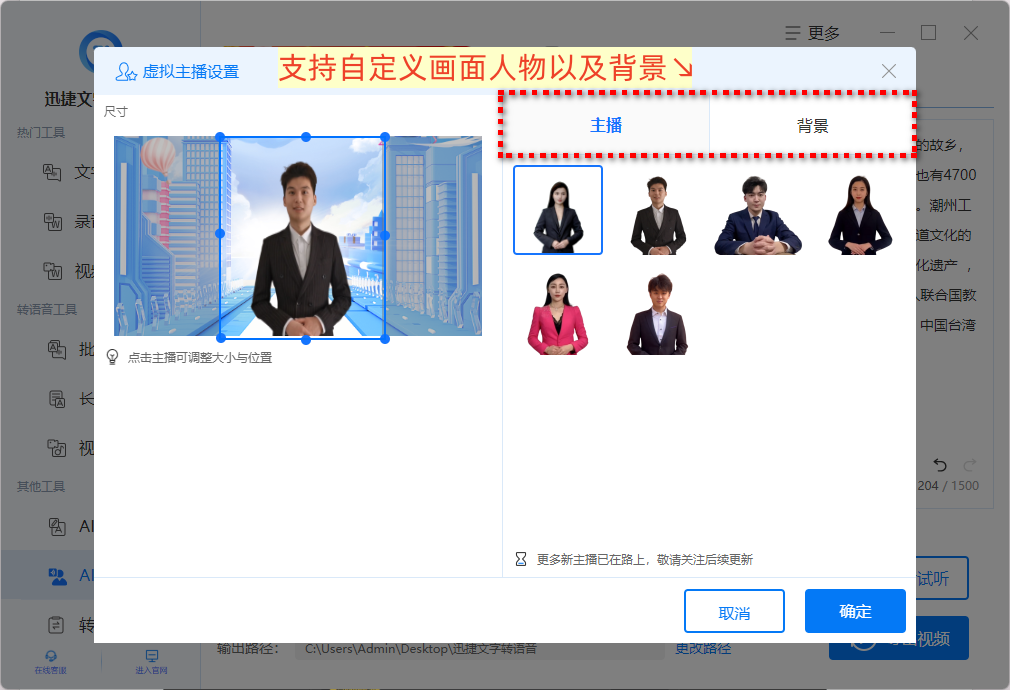
毫不夸张地说,无论我们需要怎样的播报声线,它基本上都有涵盖,直播/客服/外语/方言样样具全,选择甚是多样!
要说国内哪款视频剪辑工具最热门,那想必剪映的呼声一定不低~它本身作为一款轻量级的视频编辑工具就深受大家的喜爱,哪怕是没有任何基础的视频小白,也可以较快地上手制作出满意的成片。
与虚拟数字人有所不同的是,它主要是通过图文匹配,拼接上相关的图片/音视频素材来将简单的文本内容转换成可视化的视频。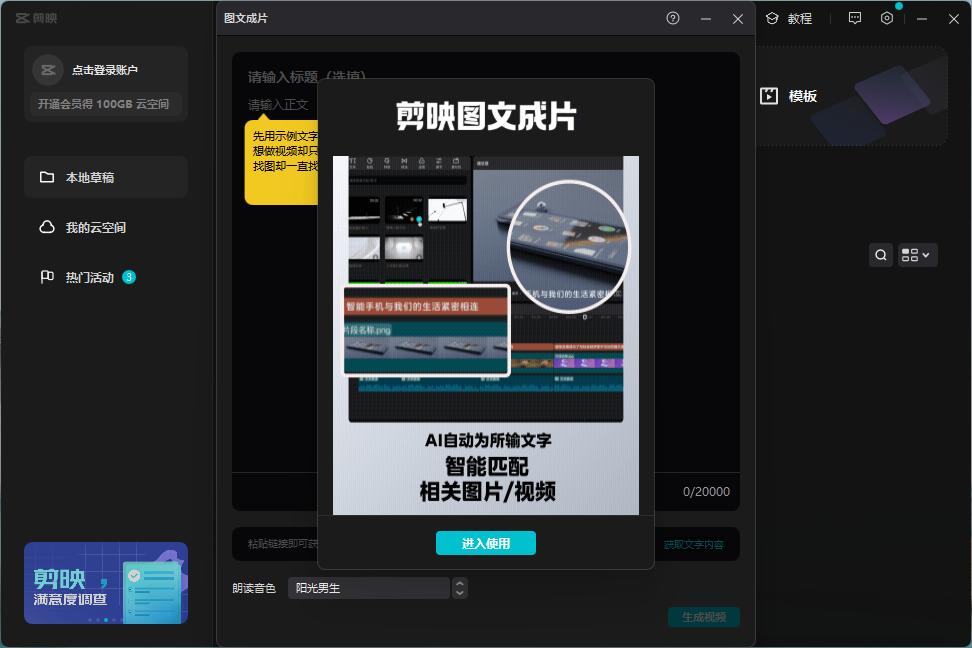
来自印度一AI初创团队之手的AI视频智能生成工具,它不仅可以做到像剪映那样的图文成片、自动匹配素材,还支持智能将长视频转换为短视频,通过AI的加持将视频素材中最精彩、最精华的部分剪辑出来。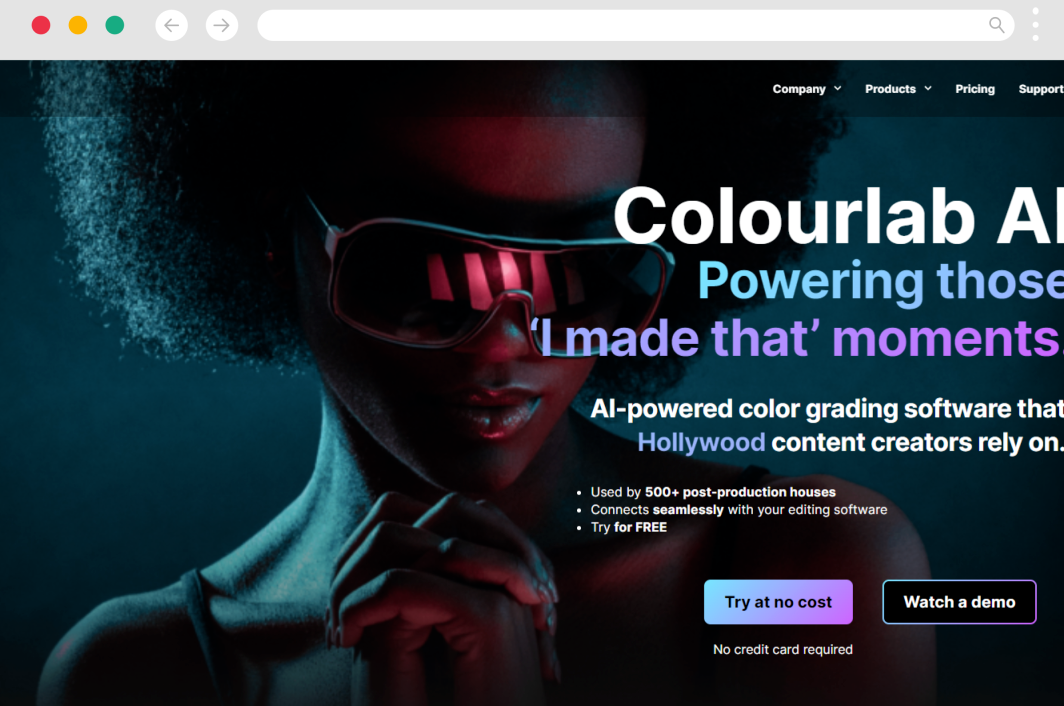
Adobe出品的一款AI自动剪辑插件,在下载安装后,它可以直接应用到PR中来使用。
在使用它辅助剪辑视频的过程中,它可以做到在最大限度上帮助我们减少剪辑视频中繁琐重复的步骤和内容,自动删除掉视频中沉默或无声的部分,将海量的视频素材智能剪辑成一个流畅、精彩的优质视频。
那么最后,我们就以国外这个在线视频制作工具来结束本次的分享~
这一视频工具同样也能够提供给我们极致的一站式视频编辑服务,支持视频剪辑/字幕添加/转场效果/背景配乐等各类常见的视频处理操作,同时还提供了不少精美的模板和场景,让我们能根据自己的需求来选择并一键套用编辑,很是便捷。
分享完毕~很高兴在这里给大家安利我日常爱用的工具,有空欢迎到 @社恐打工仔 主页逛逛~那就下次见啦~
AI 视频工具:我在AI视频生成领域的革命:Runway、Stable Video Diffusion与Pika三大神器全面解析这篇文章中提到的目前技术最好的三款视频工具。本文是根据最新消息,对AI视频工具的更新内容,关注我,实时了解AI工具及应用的最新资讯。
今天介绍的两款图片+动作生成视频项目都是国产项目,一款阿里的Animate Anyone,一款是字节跳动的MagicAnimate。两个项目的技术路线是一样的,显然属于竞品。其中阿里的Animate Anyone没有公开代码,没有demo,只是发了一篇宣传文章;字节跳动的MagicAnimate公开了代码,也公开了demo,感兴趣去试一下。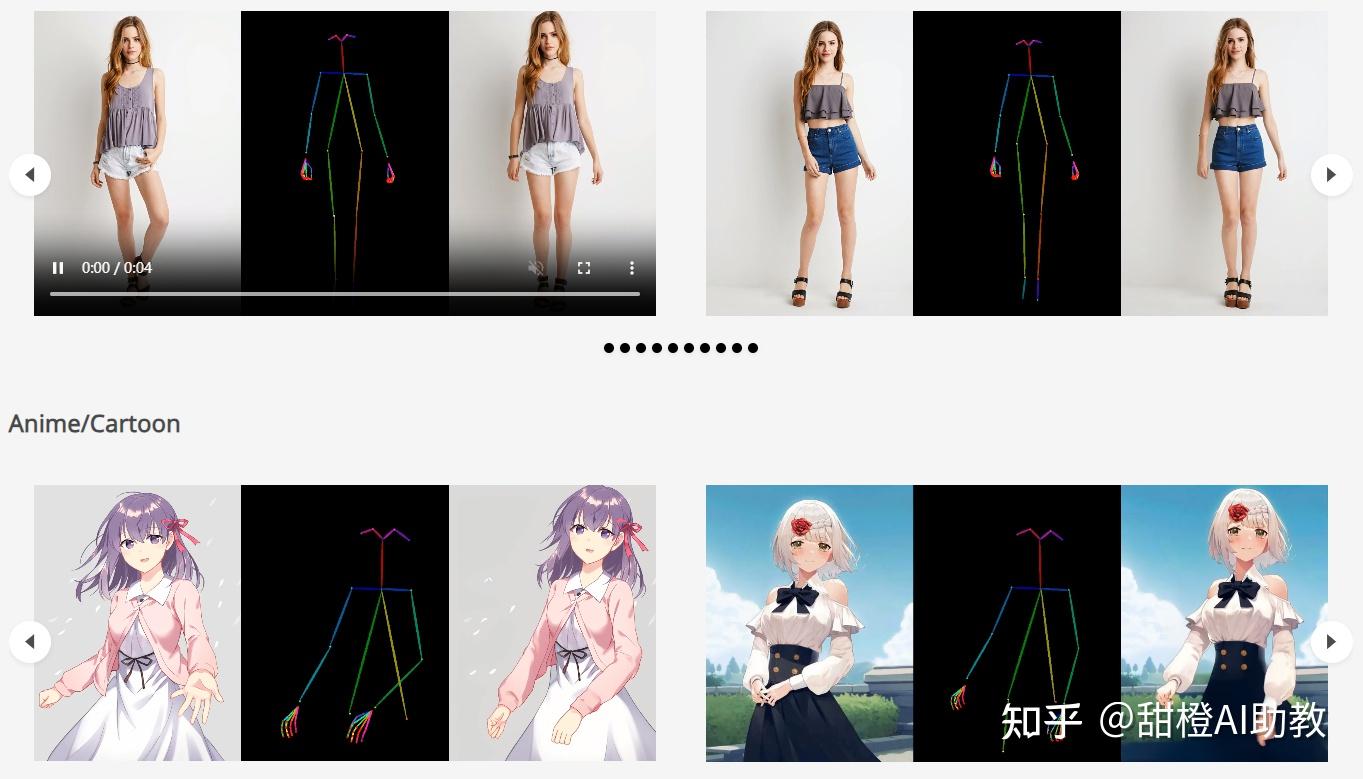 阿里的Animate Anyone
阿里的Animate Anyone 字节跳动的MagicAnimate
字节跳动的MagicAnimate
两款声音+图片生成视频项目:一个是微软GAIA;一个是字节与阿里联手推出的VividTalk产品。也就是让图片说话的两个产品。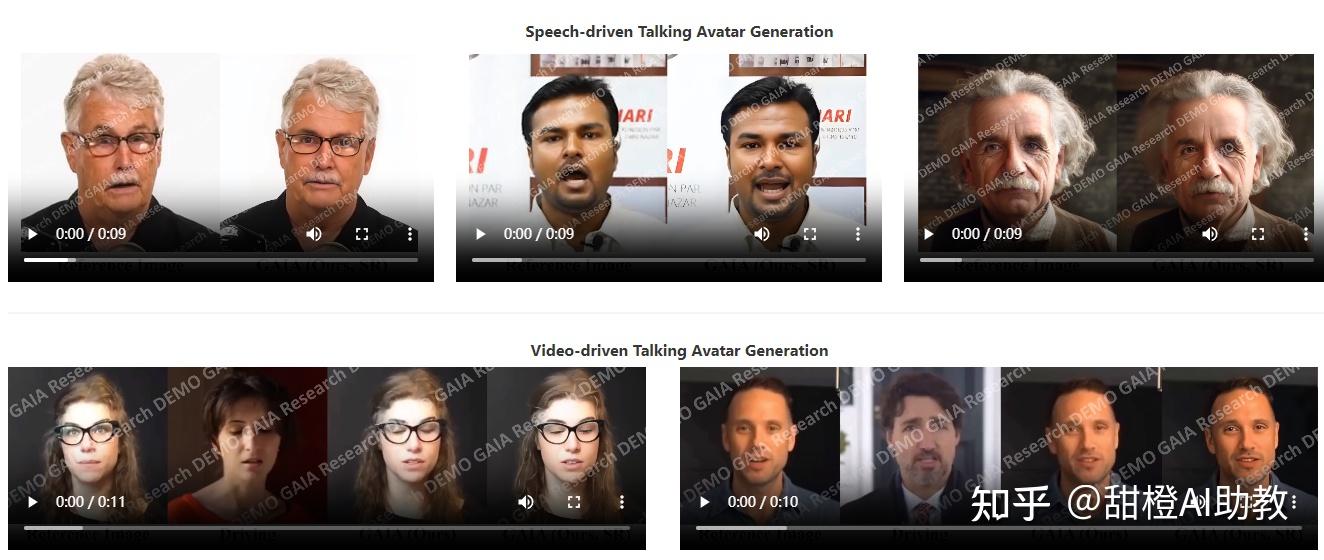 微软GAIA
微软GAIA VividTalk产品
VividTalk产品
AI 视频工具,真的越来越精彩了。
Animate Anyone是一个由阿里巴巴集团的研究人员开发的人物动画框架。这个框架能够将人物照片转化为由特定姿势序列控制的动画视频,同时保证人物外观的一致性和时间稳定性。它通过设计ReferenceNet来保留人物的精细外观特征,通过引入一个高效的Pose Guider来实现动作控制,以及通过有效的时间建模方法来确保视频帧之间的平滑过渡。 https://www.zhihu.com/video/1715682692207685632
https://www.zhihu.com/video/1715682692207685632
Animate Anyone的实现原理主要包括三个关键组件:ReferenceNet,Pose Guider和Temporal Layer。ReferenceNet是一个特征提取网络,用于提取参考图像中的空间细节。Pose Guider是一个轻量级的网络,用于将运动控制信号集成到去噪过程中。Temporal Layer则用于捕捉视频帧之间的时间依赖关系,确保角色运动的连续性。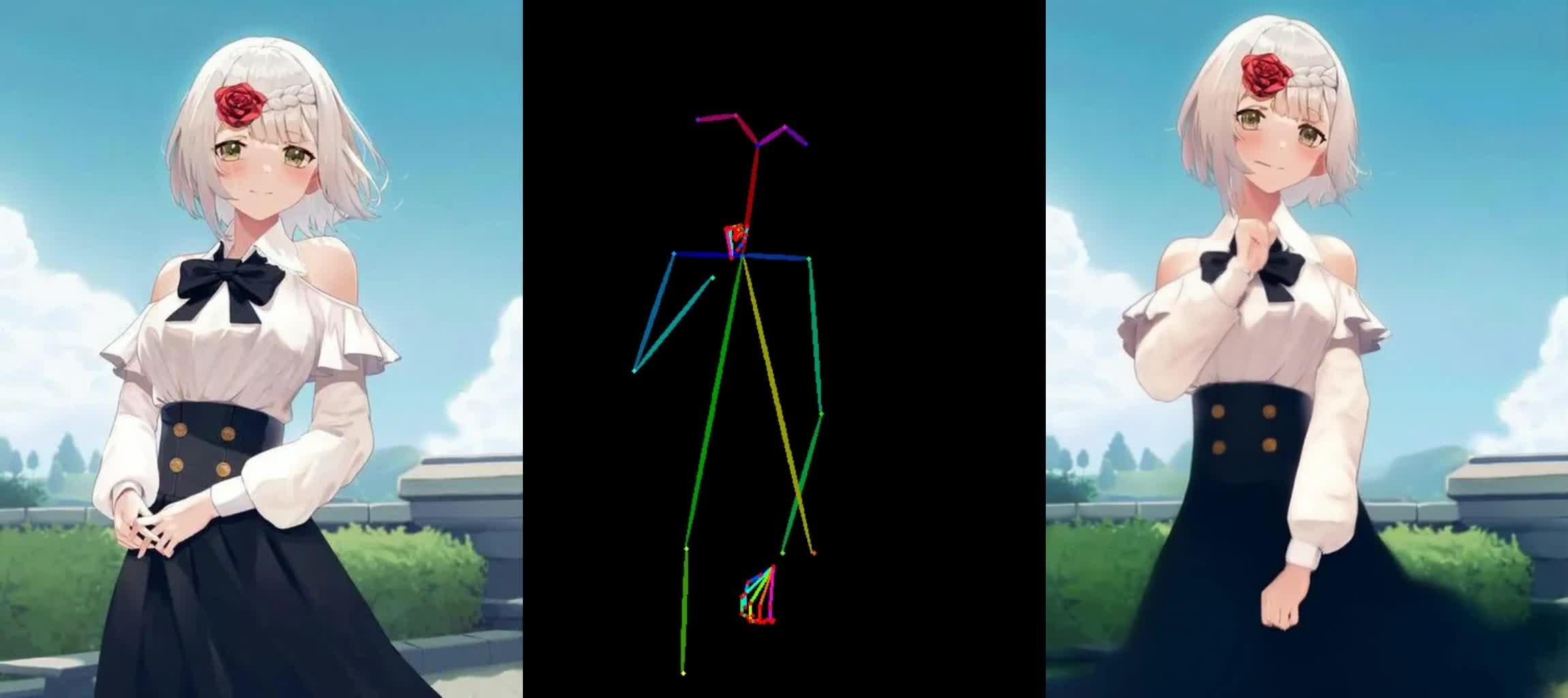 https://www.zhihu.com/video/1715683636559609856
https://www.zhihu.com/video/1715683636559609856
在应用方面,Animate Anyone不仅可以应用于一般的字符动画,而且在特定的基准测试中,如时尚视频合成和人类舞蹈生成,也表现出色。此外,它还能处理各种类型的字符动画,包括全身人物图像、半身肖像、卡通角色和类人角色。这个框架有可能成为未来各种图像到视频应用的基础方法,激发更多创新和创造性的应用。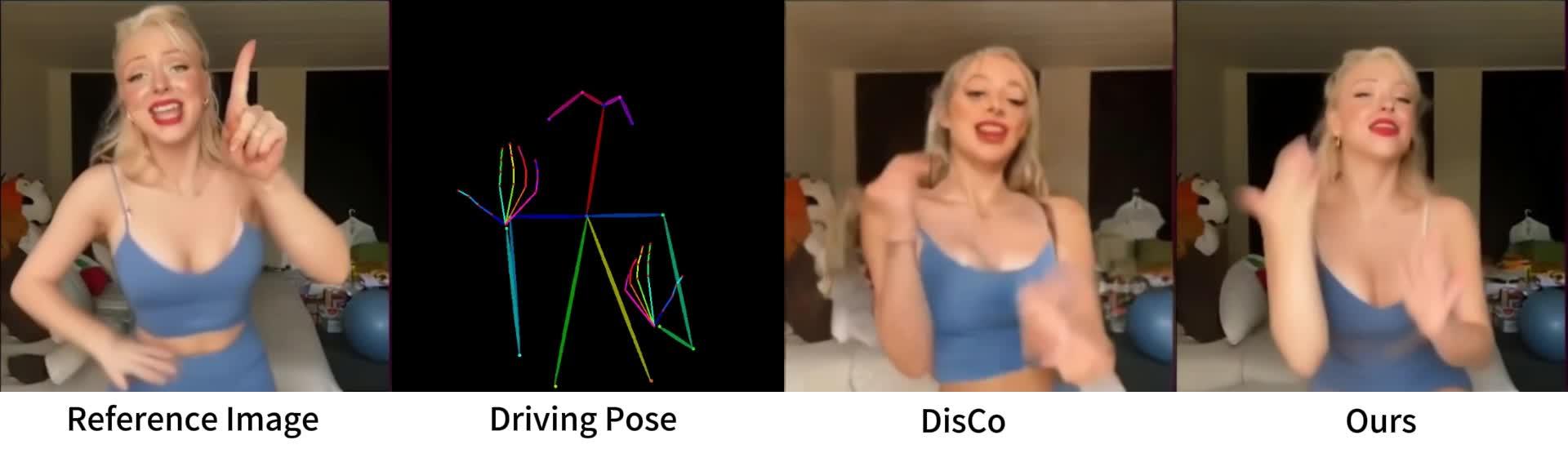 https://www.zhihu.com/video/1715683555554963456
https://www.zhihu.com/video/1715683555554963456
没有公开代码,没有demo,只是发表了一篇论文宣传,文章地址:https://humanaigc.github.io/animate-anyone/。
与阿里的Animate Anyone类似,MagicAnimate也是一种基于扩散模型的人类图像动画框架,旨在增强时间一致性,忠实地保留参考图像,并提高动画的真实感。该框架由视频扩散模型和外观编码器组成,分别用于时间建模和身份保护。为了支持长视频动画,研究者设计了一种简单的视频融合策略,以在推理过程中产生平滑的视频过渡。 https://www.zhihu.com/video/1715685269163012097
https://www.zhihu.com/video/1715685269163012097
实现原理:给定参考图像和目标DensePose运动序列,MagicAnimate使用视频扩散模型和外观编码器进行时间建模和身份保护。设计了一种简单的视频融合策略,以在推理过程中实现平滑的视频过渡。 https://www.zhihu.com/video/1715685408484990976
https://www.zhihu.com/video/1715685408484990976
应用:
1、未知领域动画:MagicAnimate可以为油画和电影角色等未知领域图像制作跑步或做瑜伽的动画。
2、结合T2I扩散模型:将MagicAnimate与DALLE-3生成的参考图像结合,制作各种动作的动画。
3、多人动画:根据给定的运动,为多个人制作动画。
与阿里的Animate Anyone相比,画面质量,人物一致性上、手部和面部动作 MagicAnimate 差一些,但MagicAnimate支持多人。
代码公开了,可以去魔改;demo也放出来了,去体验一下吧。
MagicAnimate网址:https://github.com/magic-research/magic-animate
Huggingface上的在线测试地址:MagicAnimate - a Hugging Face Space by zcxu-eric
微软的GAIA(Generative AI for Avatar)框架,是一个用于零-shot(仅使用单张肖像照片)生成逼真说话头像的视频数据驱动方法。GAIA消除了领域先验,提高了生成头像的自然度和多样性。其实现原理主要包括两个阶段:1)将每帧画面分离为运动和外观表示;2)根据语音和参考肖像照片生成运动序列。为实现这一目标,研究者收集了一个包含16K独特演讲者的大型高质量说话头像数据集,用于训练模型。
GAIA框架包括两个主要部分:一个变分自编码器(VAE)和一个扩散模型。VAE负责从视频帧中提取运动和外观表示,通过训练学会重构输入帧。扩散模型则用于根据语音特征和参考帧生成运动序列。在推理阶段,扩散模型根据输入语音和目标头像照片生成运动序列,然后与照片结合,通过VAE解码器合成输出视频。
GAIA框架具有以下功能和模式:
1、视频驱动的说话头像生成(Video-driven Talking Avatar Generation):给定一个视频作为驱动,GAIA可以生成与输入视频具有相似外观和动态的说话头像。这可以用于跨视频角色替换。 https://www.zhihu.com/video/1715689838802755584
https://www.zhihu.com/video/1715689838802755584
2、语音驱动的说话头像生成(Speech-driven Talking Avatar Generation):仅使用一张静态肖像图片和语音作为输入,GAIA可以生成与语音同步的逼真说话头像视频。 https://www.zhihu.com/video/1715689880145731585
https://www.zhihu.com/video/1715689880145731585
3、可控姿态的说话头像生成(Pose-controllable Talking Avatar Generation):GAIA支持通过设置关键姿态(如头部姿势、眼睛注视方向等)来控制生成的说话头像视频。这意味着用户可以自定义角色的姿态,同时保持唇部动作与语音同步大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!。 https://www.zhihu.com/video/1715689931417186304
https://www.zhihu.com/video/1715689931417186304
4、全可控的说话头像生成(Fully Controllable Talking Avatar Generation):GAIA允许对生成的说话头像视频进行更细粒度的控制,例如分别控制角色的嘴巴、眼睛和其他面部特征。这为生成具有特定表情和动作的逼真视频提供了更大灵活性。 https://www.zhihu.com/video/1715689965055483904
https://www.zhihu.com/video/1715689965055483904
5、文本指导的头像生成(Text-instructed Avatar Generation):GAIA框架可以响应文本指令生成说话头像视频。例如,当给定一个静态肖像图片时,模型可以根据文本指令(如“微笑”或“向左看”)生成相应的视频。
以上功能太牛逼了,你做过的照片说话的项目,有比这个牛的吗?GAIA还未公开。
这是项目地址:https://microsoft.github.io/GAIA/
VividTalk是一种新颖的通用框架,支持生成高质量、富有表现力的面部表情和自然头部姿势的说话头视频。该方法由两个串联的阶段组成:音频到网格生成(Audio-To-Mesh Generation)和网格到视频生成(Mesh-To-Video Generation)。在音频到网格生成阶段,该方法将音频映射到非刚性表情运动和刚性头部运动。对于表情运动,同时使用混合形状(blendshape)和顶点偏移(vertex offset)作为中间表示,以最大化模型的表现能力。对于刚性头部运动,提出了一种新颖的可学习头部姿势代码库(Learnable Head Pose Codebook)和两阶段训练机制。在网格到视频生成阶段,使用双分支运动VAE(Variational Auto-Encoder)和生成器将驱动的网格转换为密集的运动,并用于合成最终的视频。https://www.zhihu.com/video/1715693511116955648
VividTalk 支持对各种风格的面部图像进行动画处理,例如人类、现实主义和卡通。
使用VividTalk,您可以根据各种音频语言片段创建会说话的头像视频。VividTalk用最先进方法在口型同步、头部姿势自然度、身份保留和视频质量方面效果不错。
VividTalk项目地址:https://humanaigc.github.io/vivid-talk/
就这样了,关注我,跟踪AI技术的最新进展。
神采PromeAI,一个在线AI图像编辑处理网站,支持文生视频和图生视频,国内版和海外版会有一点区别。
目前文生视频仅在海外版上线,通过一句简单的话,几个描述性的词语,就能生成1条视频,还可以选择视频风格、自定义画面尺寸、控制画面主体运动的快慢。探索AI的无限可能性 - 神采PromeAI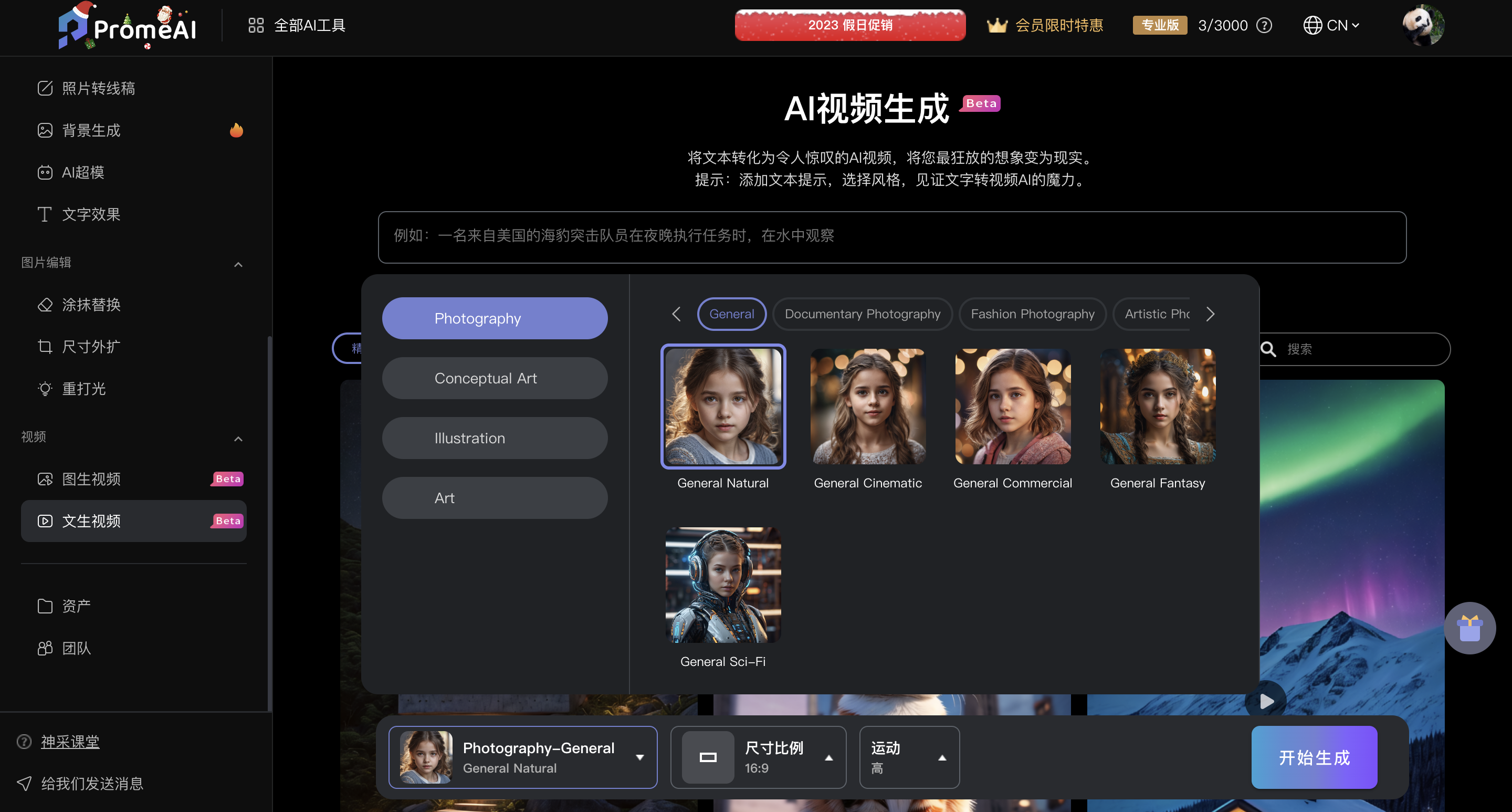
“强大的液体爆炸,葡萄,紫色背景。” https://www.zhihu.com/video/1719386509491257345
https://www.zhihu.com/video/1719386509491257345
“核弹爆炸,夜间产生巨大冲击波。” https://www.zhihu.com/video/1719386964435066880
https://www.zhihu.com/video/1719386964435066880
从用户体验角度来讲,生成一条视频需要1-2分钟,每条视频的时长为4s,目前主流文生视频平台生成的视频长度也只有2-4s。从生成效果来讲,独家的算法和运动模型使得画面更真实运动效果更连贯。
这个月初,神采PromeAI国内版和海外版都上线了图生视频功能,上传一张图片,不需要任何关键词就能将静态图片转变为动态视频,给大家展示一下国内图生视频的效果。探索AI的无限可能性 - 神采PromeAI
栩栩如生的龙。 https://www.zhihu.com/video/1719393495884853249
https://www.zhihu.com/video/1719393495884853249
旋转展示的摆件。 https://www.zhihu.com/video/1719394023805206528
https://www.zhihu.com/video/1719394023805206528
破浪行驶的船只。 https://www.zhihu.com/video/1719394541155770368
https://www.zhihu.com/video/1719394541155770368
燃烧的蜡烛。 https://www.zhihu.com/video/1719394793455722496
https://www.zhihu.com/video/1719394793455722496
还可以涂抹图片局部,让选中的部分动起来,这样对画面的控制更灵活更精确,也减少了图生视频常见的画面扭曲问题。此项功能目前还在内测阶段,不日也将上线,大家可以先期待一下。 https://www.zhihu.com/video/1719395231219486720
https://www.zhihu.com/video/1719395231219486720
神采PromeAI的文生视频和图生视频功能目前都处于公测阶段,所有人均可以免费体验,不会拍摄不会剪辑没关系,有了这个低门槛的AI生成视频工具,普通人也有可能成为优秀的视频内容创作者!









评论留言